

Anatomy of an AI Agent
AI agents aren’t a single breakthrough, but rather systems made up of interacting components
AI agents are often presented as if they’re a single breakthrough technology. In practice, they’re systems made up of several components all working together toward a goal. And once you start building them, you realise the hard part wasn’t getting an agent to work. It was getting it to work reliably, repeatedly, and in environments that resemble the real world instead of a polished demo.
That’s part of the reason I wanted to start this newsletter here, with fundamentals. Before the frameworks, abstractions, and “10x autonomous employee” headlines, it helps to understand the actual moving parts underneath these systems.
For builders navigating the move from models to agents
AI agents follow a typical pattern and can be broken down into three fundamental components: model, tooling interface, and memory and knowledge.
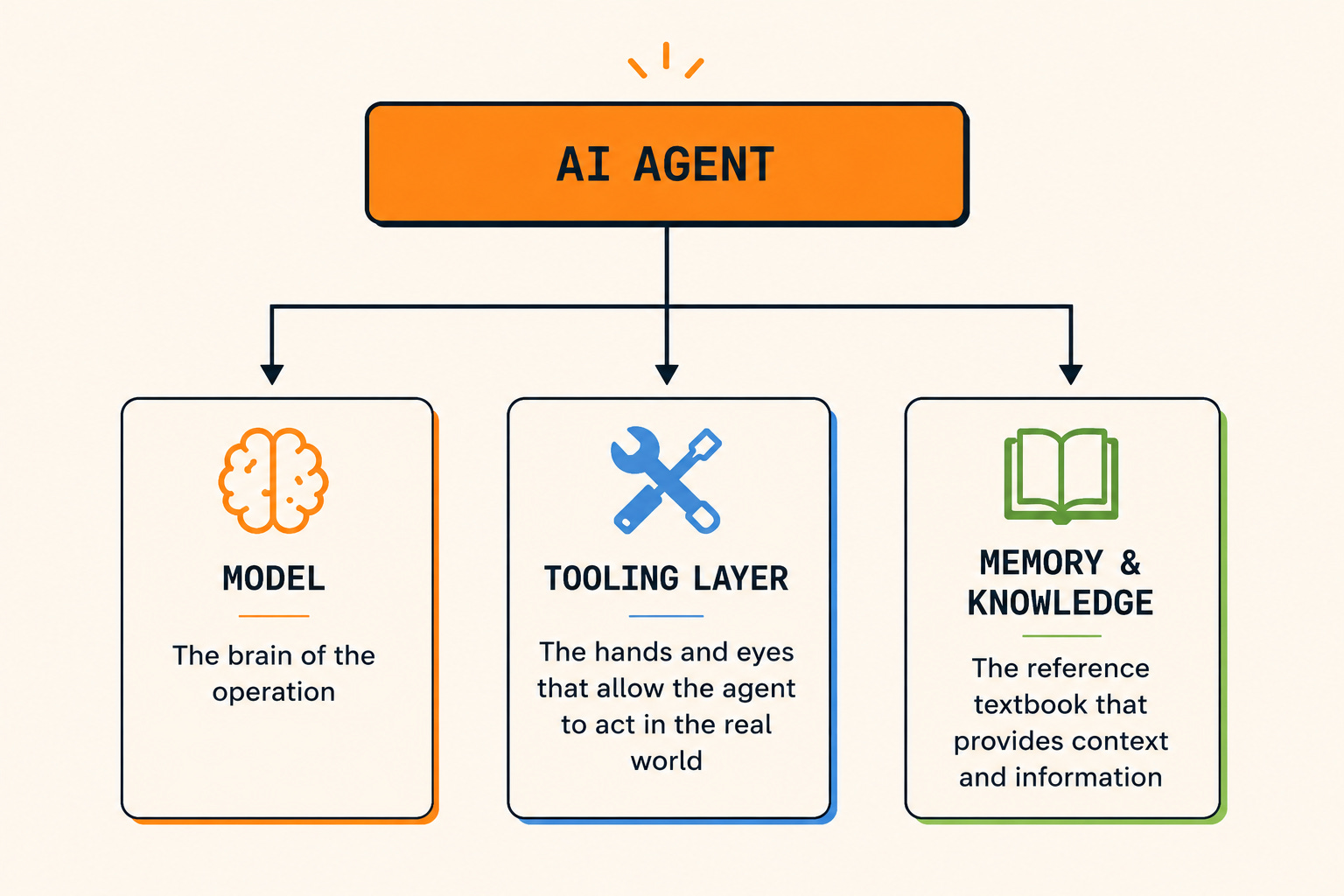
Production-grade agents depend heavily on how well these components coordinate with one another. A capable model paired with poor tooling or weak memory management will, without a doubt, produce unreliable systems.
Model
The model is still the brain of the agent. It’s the part doing the reasoning, interpreting inputs, deciding what to do next, and trying to recover when things go sideways.
But the more you look at production systems, the harder it becomes to talk about models in simple leaderboard terms. The “best” model usually depends on what kind of compromises you’re willing to live with.
Some models are fast enough to feel seamless, but start struggling once tasks become more complex. Others reason well but move slowly enough to make the whole experience feel heavy. Some are great at coding, some handle multimodal workflows better, and some begin falling apart the moment you push them into long-running tasks with too much context.
And then there’s the strange reality that models don’t just differ in capability. They differ in personality almost. Different blind spots, different reasoning habits, different confidence levels, different failure modes. Some hallucinate more aggressively. Some become overly cautious. Some feel oddly persuasive even when they’re wrong.
Certain aspects of performance and bias, such as knowledge cut-off dates and political leanings, can be resolved by tactics such as retrieval augmented generation (RAG), nuanced prompting, or post-train refinements.
Most AI agents are not powered by entirely different “agent models.” Many of them rely on the same families of frontier models, whether that’s GPT-class, Gemini-class, or Claude-class systems. What differs between these applications is not the model but the instructions provided to the model and how the model interacts with other components.
These “instructions” are provided to the model by defining a system prompt, which essentially defines the model’s role inside the system. When you really get down into it, a surprising amount of agent development involves refining prompts, adjusting tool descriptions, and reshaping interaction flows to make systems behave more reliably.
Control logic framework
Another important part of an AI agent is the control logic framework: the loop that lets the system observe what’s happening, reason about what to do next, take action, and then repeat that process until it reaches a goal.
What’s interesting is that this loop often does not happen “inside” the model itself. In many cases, it’s the surrounding agent framework that keeps the cycle running, feeding outputs back into the model, deciding when tools should be invoked, and determining whether another reasoning step is needed.
The process looks something like this:
Read user’s goal and create action plan
For each step in action plan:
Create action inputs
Execute action
Get result
Add result to memory
Modify action plan if necessary or if goal not achieved
If goal is achieved:
Return output to user
Different agent frameworks implement this loop differently, but most follow some variation of planning, acting, evaluating, and repeating. Patterns like CoT and ReAct show up constantly underneath modern agent systems.
Some frameworks even get a little strange with it. One pass generates the answer, and another pass comes back to critique the reasoning like an internal reviewer hovering over the system’s shoulder.
Tooling interface
One of the biggest differences between a normal LLM and an AI agent is that the agent can actually interact with the outside world instead of just generating tokens inside a chat window. That capability comes from the tooling interface, which gives the agent a structured way to decide when and how actions should be executed.
An email assistant, for example, might be equipped with actions that look something like this:
Action #1: Send an email
Description: Sends an email to a user
Parameters: to_email_address, email_subject, email_body
Action #2: List all emails
Description: Lists all emails, including email_id
Parameters: search_term (optional)
Action #3: Read an email
Description: Returns the content of an email
Parameter: email_id
Once these tools are available, the agent’s model and control logic framework decide when they should be used and what inputs they need.
An email assistant, for example, might search for emails related to a “coffee expansion proposal,” read through the relevant threads, generate a summary, and then send that summary to a manager. Underneath, the agent is simply chaining together a series of tool calls and feeding the outputs back into the reasoning loop.
The mechanics differ slightly depending on the framework being used, but the overall pattern stays fairly consistent. The agent needs awareness that the tools exist, a way to execute them, and a way to pass the results back into the model.
Memory and knowledge
Memory and knowledge are another part of what makes agents intelligent instead of just reactive. The two are related but slightly different.
Memory is about what the system remembers from interactions and previous context, while knowledge is about what it can retrieve from external sources when needed. In both cases, the goal is to give the model enough relevant context to make better decisions and produce more useful responses.
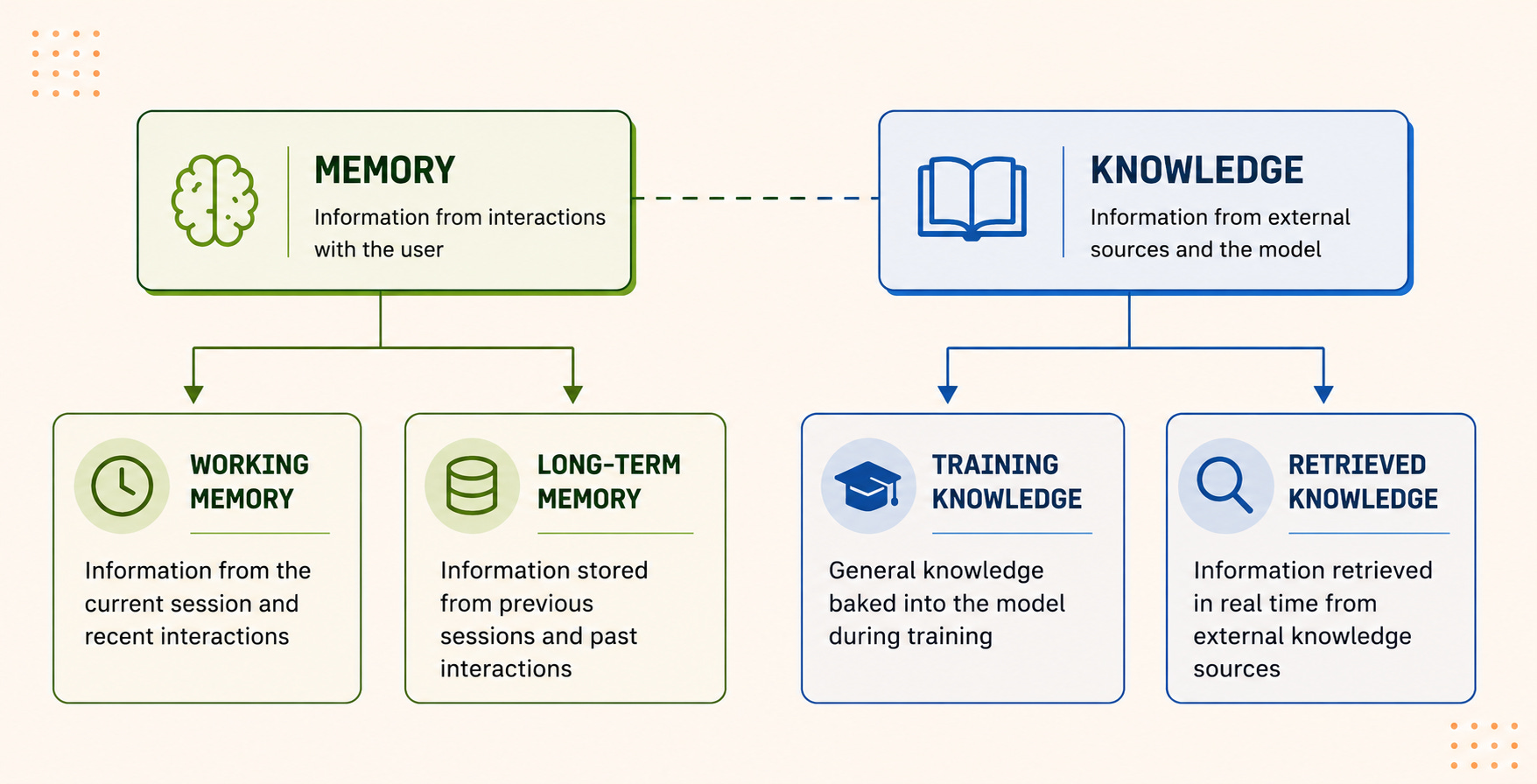
Let’s talk about each concept and how it’s used to provide more context to the AI agent. There are typically two types of memory: working and long-term.
Working memory
Working memory is basically the agent’s short-term memory: the running context from the current interaction.
It’s what allows systems like ChatGPT to understand that when you ask “How big is it?” after asking about the sun, the word “it” still refers to the sun instead of something completely unrelated.
Underneath, this usually works by continuously feeding recent conversation history back into the model as context. That’s what makes follow-up questions and multi-step conversations possible in the first place.
But this memory is limited. Context windows eventually fill up, older information starts dropping out, and frameworks have to decide what information is worth keeping around. A surprising amount of agent design ends up revolving around that question alone.
Long-term memory
Long-term memory is what allows an agent to carry information across sessions instead of treating every interaction like a completely fresh start. Without long-term memory, an agent is basically stateless: every request exists in isolation. With memory, the system can begin recalling preferences, past interactions, recurring tasks, or relevant context from earlier conversations.
This usually means storing information in some external database or memory layer that the agent can retrieve later through tools. So an email assistant, for example, might remember how you typically write messages, who you communicate with most often, or the kinds of follow-ups you usually prefer. Your AI agent may have the following tooling, which enables it to store and recall memories:
Action #1: Store information
Description: Stores important information about the user
Parameters: information
Action #2: Read information
Description: Retrieves important information about the user
Working memory is usually the easy part. Most systems already know how to keep track of the current conversation. Things get more interesting once agents need to remember information across sessions or retrieve context from external knowledge sources in real time. That’s usually where extra infrastructure starts creeping in: vector databases, retrieval pipelines, memory stores, ranking systems, all the machinery needed to stop the agent from feeling like it has permanent short-term memory loss.
Knowledge is slightly different from memory, though. Memory is about recalling previous interactions. Knowledge is about pulling in relevant information from outside sources like documents, databases, file repositories, or internal company systems.
And the moment agents start operating inside real workflows instead of isolated chats, that distinction starts mattering a lot more.
Training knowledge
Training knowledge refers to the information already baked into the model through its training data. It’s why an LLM can answer something like “How big is the sun?” immediately without needing to search the web or retrieve a document first.
That capability is still the thing that makes these systems feel a little unreal sometimes. A model can absorb enormous amounts of general knowledge and then reshape it fluidly around whatever the user is asking.
But once you move into AI agents, that baked-in knowledge starts becoming less useful on its own.
Agents usually need information that’s contextual, recent, proprietary, or tied to a specific workflow. And the model’s training knowledge can’t help much there. It doesn’t know what happened after its cut-off date, it can’t see your internal documents, and it definitely doesn’t know why your finance team suddenly renamed twelve folders last Thursday.
Which is why modern agents now depend on retrieving information dynamically instead of relying purely on what the model already knows.
Retrieved knowledge
Retrieved knowledge is where agents start becoming genuinely useful instead of just broadly knowledgeable. Unlike training knowledge, which is frozen at training time, retrieved knowledge happens in real time. The agent pulls relevant information from documents, databases, APIs, internal systems, or the web, depending on what the situation requires.
An HR agent is only useful if it can retrieve actual company policies instead of confidently inventing them. A sales agent needs live CRM context, not generic training data. The intelligence of the system comes less from what the model already “knows” and more from how well it can retrieve and use external context while operating.
Once you break agents down into these moving parts, the current ecosystem starts feeling less like a race toward “AI autonomy” and more like an ongoing experiment in coordinating increasingly complicated systems.
This article was adapted from Building Agents with OpenAI Agents SDK by Henry Habib, a practical guide to designing and building real-world agentic systems using the OpenAI Agents SDK.
The book goes much deeper into:
tools and MCP integrations,
memory and RAG architectures,
multi-agent orchestration and handoffs,
tracing and guardrails,
production considerations,
and hands-on projects that evolve from simple workflows into full agentic systems
If you’re trying to move beyond experimenting with agents and toward actually shipping them, it’s a genuinely useful resource.